








Written by Marcus Hartmann, Felix Baumann, Maria Foelster and Joshua Wenn. Data is the fundamental building block in the field of artificial intelligence (AI), providing the potential for innovation and enabling Generative AI (GenAI) to showcase its capabilities. GenAI, a unique area within AI, learns from vast datasets to produce content, artwork, and writings, with data being the key to these creations often rivaling or exceeding human achievements. But why exactly is that?
Diverse and high quality data sets are a must for several reasons. For starters a wide array of data enables generative AI models to create a wider and more adaptable range of results. This is crucial for tasks such as generating text, synthesizing images, or composing music, where various individuals may possess distinct preferences and needs. By being trained on diverse data, the AI can effectively meet the demands of a broad audience and avoid producing biased results.
The role of data in Generative AI
“In order for GenAI to operate with utmost efficiency and effectiveness, a vast assortment of diverse data is imperative.”
AI models that generate content can unintentionally create biased or offensive material if they are trained on a restricted and prejudiced dataset. The greater the inadequacy of data quality, the higher the probability and magnitude of bias. Employing varied and top-notch datasets aids in diminishing this bias by introducing the model to a wider array of viewpoints and encounters making them more robust.
To put it briefly, having a wide range of top-notch data sets is crucial when it comes to teaching reliable, flexible, morally upright, versatile AI models that can tackle an extensive array of tasks and inputs. It’s an important factor in ensuring the effectiveness and responsible use of AI in various applications.
Now that we know why a diverse range of data sets is important next up is how to achieve such diversity. A proven method at PwC is the data acquisition process.
“Data acquisition describes a data type-dependent and standardized process for capturing and making data available for later analysis and use.”
It is important to note that data acquisition refers to data that has been purchased through a provider. It is in contrast to data integration, which refers to the process through which we make data that PwC already owns available. At PwC DE the Chief Data Office has the Service Ownership for Third Party Data Acquisition with following responsibilities and its advantages:
Responsibilities
- Provide a central administration entity for structured and centralized data acquisition
- Get the most value from data by encouraging multiple users to adopt existing dataset through e.g. licencing extension
- Established strategic requirements that data sets must meet
Advantages: A coordinated approach to data acquisition reduces costs and risks
- Cost saving: Coordinating data acquisitions reduces the number of redundant datasets and creates transparency about current availability.
- Visibility: Traceability of data sources and connections through a clear knowledge of what data is available.
- Structured data purchase: All acquired third-party datasets must go through a review to ensure strategic requirements (e.g. a clear business case, uniqueness, strategic fit) are met.
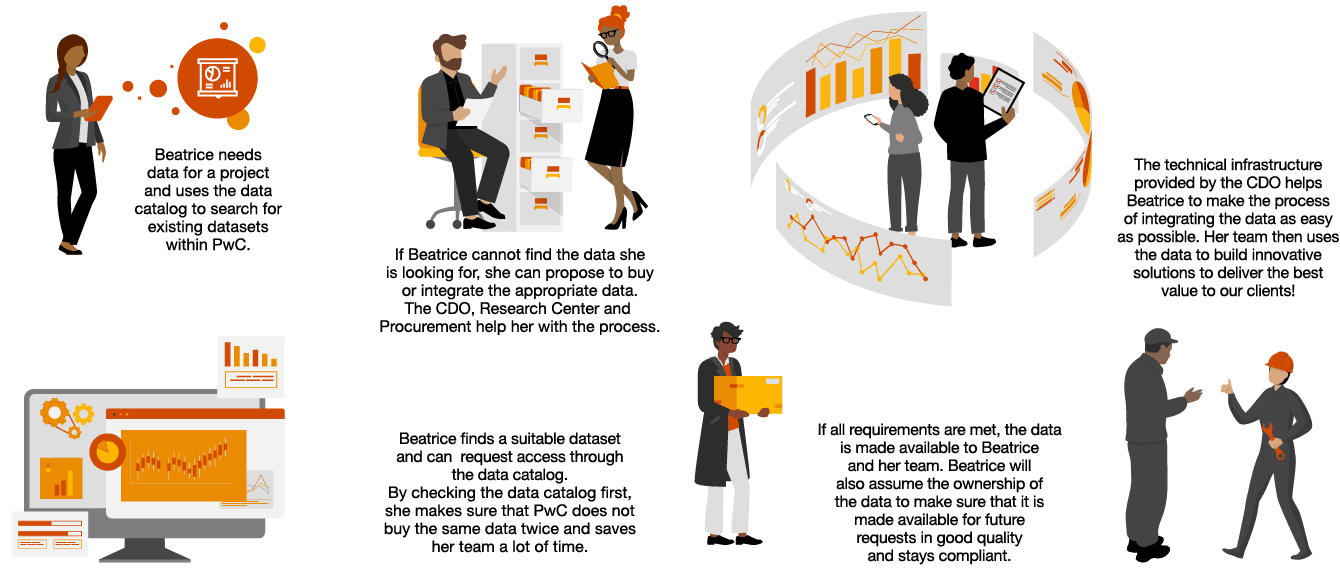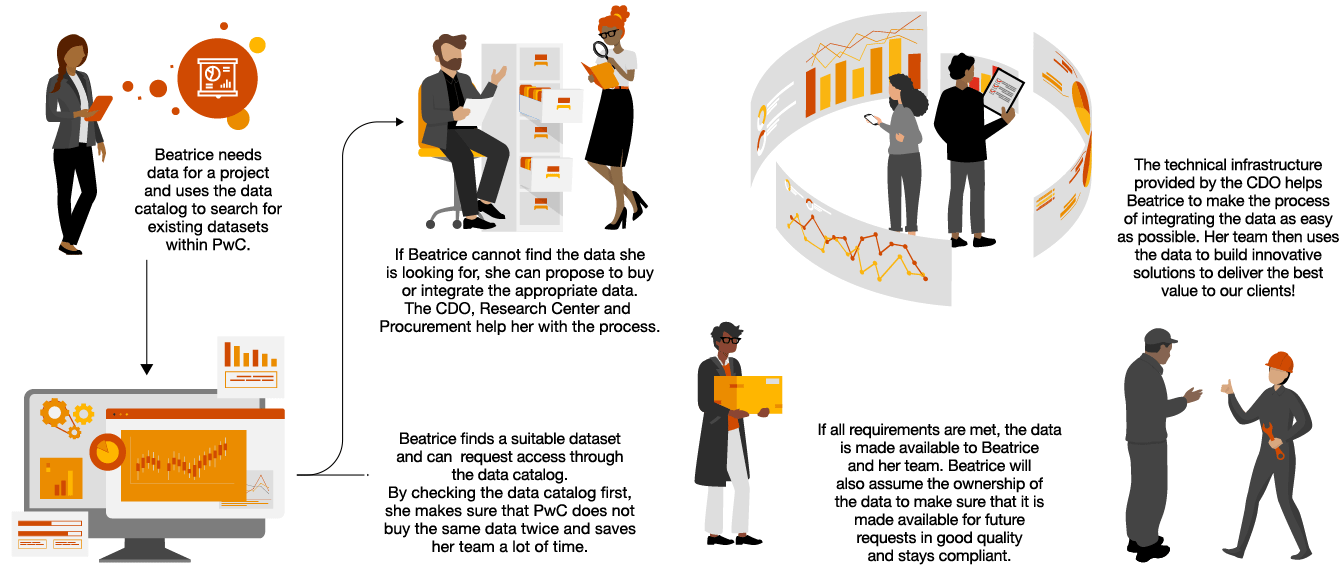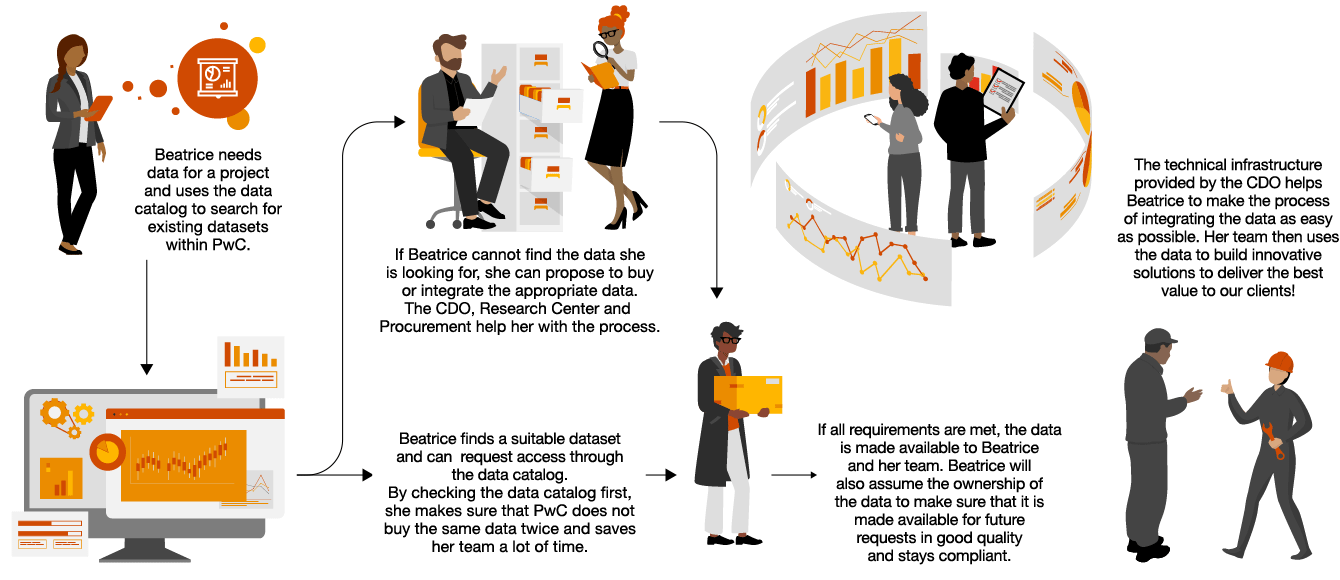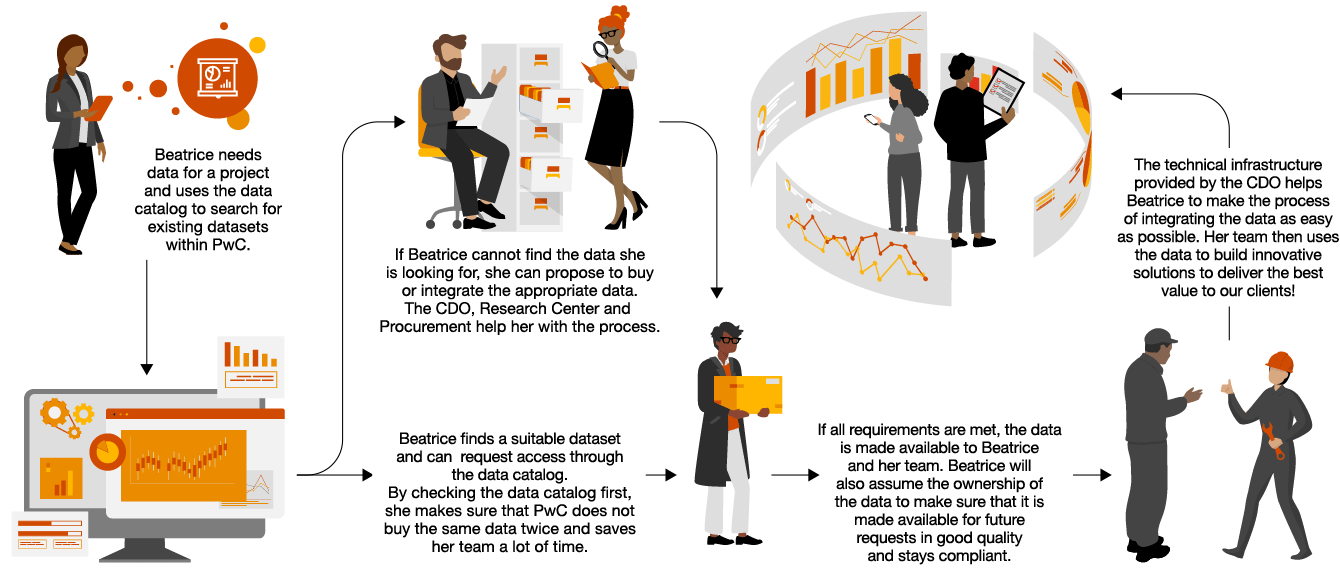
“Policies and use cases need to be defined to guide all industries on their GenAI journey – supported by a well established data governance framework.“
Understanding the data lifecycle
It becomes simpler to comprehend various subjects when they are explained through a systematic approach. To provide context: PwC follows the data lifecycle in its operations. Similar to any merchandise, data also undergoes a lifecycle.
Data cannot be captured at one single point. A holistic view of its entire lifecycle enables us to manage data so that it is fit for purpose at any given time. The data lifecycle covers the period starting from the first contact with the data when it is generated to the last point of contact, the final deletion. This general process describes the flow of data through an organization. Data passes through various points in the data lifecycle.

Collect
When collecting data GenAI can be used to augment collected data. This means it has the ability to add further samples or instances to expand the data set which leads to a more robust analysis. GenAI can also be helpful to add easier to consume documentation for data sources, based on specific metadata.
Risk: Adding GenAI to your data collection step enhances the risk of data biases, as it can perpetuate biases in your training data, and possible privacy concerns.
Do:
- Data Diversity: It is crucial to gather a diverse range of data to ensure the successful application of Generative AI models.
- Data Documentation: Make sure to thoroughly document how you collected the data, including details about its sources, collection methods, and any consent forms obtained.
Don’t:
- Overcollection: Be cautious not to collect an excessive amount of irrelevant data for your project, as it could potentially put your privacy and security at risk.

Process
The processing of data can be supported with GenAI in a way that it can assist you in the cleansing of data which will increase the data quality, and the processing time.
Note: A data quality of 100% will also not be reached with GenAI. For mission critical applications you would still need a human in the loop.
Risk: When processing data, particularly when employing systems or models that do not belong to you, it is crucial to anonymize the data. Consequently, while utilizing GenAI for data processing, there exist various situations that may result in the inadvertent disclosure of information such as excessively transparent models or inadequate and unsuccessful anonymization techniques. Such instances might enable sensitive information to fall into unauthorized possession.
Do:
- Data Validation: Verify the data processing steps to prevent data leakage.
- Data Quality Assessment: Regularly assess data quality after processing to ensure data integrity.
Don’t:
- Excessive Data Alteration: Avoid excessive data manipulation that may compromise the original data's accuracy and integrity and quality. This can be done through generating clean data or replacing missing or erroneous values.

Analyze
Utilizing data synthesis, GenAI has the capability to offer supplementary data points for analysis or facilitate the investigation of hypothetical situations, provided that the data follows recognized patterns.
Risk: It is recommended to exercise caution as this may result in overfitting, potentially producing data that does not accurately represent the genuine underlying patterns. Additionally, it is important to make sure that any generated data is adequately labeled or documented to avoid misinterpretation.
Do:
- Cross-Validation: Use cross-validation to assess the quality and generalizability of generated data.
- Validation Metrics: Establish appropriate validation metrics to evaluate the generated data's fidelity.
Don’t:
- Overreliance: Don't solely rely on generated data; combine it with real data for comprehensive analysis.
“Look out for data hallucinations, as well as data security and privacy issues during every step.”
“Data hallucinations” are situations in which the AI model produces completely made-up or wrong outputs, often without any connection to the training data or input given. These results can be misleading, irrelevant, or even nonsensical. Hallucinations may arise due to limitations in the model's training data or structure and can pose problems in applications where accuracy and faithfulness to the input data matter a lot, like natural language processing or image generation. For instance, let's consider a text generation tool powered by generative AI. It might experience hallucinations by generating sentences or information that is factually incorrect or unrelated to what was provided as input. Tackling and minimizing these hallucinations remains an ongoing challenge during the development of generative AI models because it is crucial for ensuring trustworthy and reliable content generated by AI systems – especially when precision and truthfulness hold utmost importance within specific applications.

Store
Through using generative models it is possible to compress, thus reducing the storage space needed for certain datasets without losing essential features needed from the data.
Risk: The possibility of storing more data puts you at risk from a data retention point of view.
Do:
- Data Retention Policy: Implement a clear and compliant data retention policy, especially for generated data.
Don’t:
- Insecure Storage: Avoid storing data in unsecured locations or formats.

Share
In the sharing process GenAI can be used to create synthetic or anonymized versions of data for sharing, preserving privacy while allowing third parties to use representative data.
Risk: The act of sharing sensitive information, even when adequately anonymized, may potentially result in violations of privacy or unauthorized exploitation for unintended objectives.
Do:
- Consent and Agreements: Ensure that data sharing adheres to consent agreements and legal requirements.
- Data Minimization: Share only the necessary data, keeping it as minimal as possible.
Don’t:
- Uncontrolled Sharing: Avoid sharing data without proper consent, agreements, and control mechanisms.

Archive
Concerning archiving data, GenAI is able to assist you in before mentioned ways, like summarizing, compressing or analyzing archived data. Moreover, it can aid you in categorizing and arranging stored information. Through training models to identify patterns and content within the data, GenAI is able to automatically assign relevant keywords or labels to facilitate easy searching and retrieval of archived information.
Risk: If not carefully managed, GenAI may inadvertently alter or distort archived data, potentially leading to data loss or degradation.
Do:
- Data Preservation: Either make use of GenAI to enhance data conservation by generating duplicate copies, recovering damaged data, and guaranteeing that the data will be accessible in upcoming formats or systems.
- Data Compression: Or Utilize GenAI to decrease storage requirements through compression techniques that maintain the accuracy of information.
- Data Transformation: Employ GenAI to convert data into standard, open, or long-lasting preservation formats for future compatibility.
- Regular Quality Assessment: Regularly evaluate the quality of stored data using Generative AI technology to identify deterioration or irregularities.
- Data Summarization: Leverage GenAI to generate brief summaries or outlines of stored data, improving its usability.
Don’t:
- Data Leakage Oversight: Ensure that GenAI models used in archiving are properly configured to prevent data leakage or the exposure of sensitive information.
- Lack of Data Recovery Measures: It's important to not depend exclusively on GenAI for restoring data without incorporating extra backup and recovery tactics.

Delete
GenAI has the capability to determine which data should be removed, when it should be deleted, and for what reasons according to specific policies. Additionally, in cases where sensitive data needs to be erased, GenAI can produce substitute information in order to preserve the integrity of databases and applications that depend on the eliminated data.
Risk: When using GenAI in the data deletion process it can leave residues, so that the data can be retrieved by unwanted parties. Also if not properly configured it can delete data which shouldn’t be deleted and are irretrievably lost.
Do:
- Secure Deletion Techniques: Ensure the safety of sensitive information by employing secure techniques for data deletion, such as overwriting or cryptographic deletion, to prevent any potential retrieval.
- Dependency Analysis: Before carrying out deletion tasks, thoroughly examine data dependencies within systems and applications to identify possible consequences.
- Data Replacement: To maintain the structure and functionality of systems that rely on deleted data, utilize GenAI when necessary to generate replacement data.
Don’t:
- Incomplete Deletion: Avoid incomplete or insecure data deletion methods that leave traces of data behind.
- Rushed Deletion: Take your time during the process of deleting data; rushing can lead to mistakes. Assess dependencies carefully and guarantee a secure deletion procedure.
- Data Deletion Without Backup: Don't delete data without a proper backup or data recovery plan in place, especially if the data is critical or irreplaceable.
- Deletion Without Documentation: Always document the entire process of deleting data, including reasons for deletion and any actions taken.
Summary
Data holds a significant position in the realm of Generative AI, serving as one of its fundamental components. Throughout the entire data lifecycle, there exist extensive possibilities for GenAI to contribute towards achieving enhanced efficiencies.
“Ensure comprehensive integration between corporate strategy and data strategy.”
It becomes imperative to establish a solid foundation in data management within the company and foster a culture that values data among both employees and management. This needs to be integrated into the company’s overarching goals, then translated into a data strategy and implemented throughout operational structures.
Management plays a critical role in developing guidelines that encompass these aspects while fostering an overall environment focused on data. Without proper data governance, guidelines, and fundamental data literacy, there is potential for Generative AI to present risks which need to be reduced as much as possible.
“Whenever you use data at PwC there are one or several steps from the Data Value Chain that can help you work more efficiently. While the ideation and product management remain with you, the CDO enables and coordinates the processes that drive the value creation. The CDO’s Data & Content Team provides the foundational structure for both the technical realization, and the governing and operational capabilities such as a data catalog, a data ecosystem. The Data & Tech team builds the infrastructure that underpins all operations. Lastly, various layers of compliance and risk complete the picture which the CDO can help you navigate.“
PwC has both in-house and external knowledge, as well as state-of-the-art resources concerning data that can be efficiently used to leverage the immense potential of GenAI. If you need any help or support regarding this issue, feel free to reach out to our team of proficient specialists who are always ready to assist you.
Our webcast series
GenAI – What decision-makers need to know now
Contact us





Christine Flath
Leitungsteam Familienunternehmen und Mittelstand und Ihre Ansprechpartnerin für Transformationsthemen, PwC Germany






